KNN 算法原理与实战指南
一、 什么是 KNN 算法?
KNN (K-Nearest Neighbors),即 K-最近邻算法,是机器学习中最简单且直观的算法之一。它属于有监督学习,既可以解决分类问题,也可以解决回归问题。
其核心思想可以用一句话概括:“近朱者赤,近墨者黑”。
分类场景:通过“投票法”决定。新样本的类别由其最近的 K 个邻居中出现次数最多的类别决定。
回归场景:通过“均值法”决定。新样本的预测值是其最近的 K 个邻居目标值的平均数。
二、 距离度量算法
1. 欧氏距离
欧氏距离是最直观的度量方式,即欧几里得空间中两点间的直线距离。
定义:计算各维度差值的平方和,再开平方根。
公式:
2. 曼哈顿距离
曼哈顿距离也称为“城市区块距离”,模拟了在网格状街道上从一个十字路口到另一个十字路口的行走路径。
定义:计算对应维度差值的绝对值并求和。
公式:
3. 切比雪夫距离
切比雪夫距离起源于国际象棋中王(King)的移动方式:王走一步可以移动到相邻 8 个方格中的任意一个。
定义:各维度差值绝对值中的最大值。
公式:
4. 闵可夫斯基距离
这并非一种全新的距离,而是对上述三种距离的数学推广。
公式:
参数p 的变化:
当p=1 时,等同于曼哈顿距离。
当p=2 时,等同于欧氏距离。
当p \to \infty 时,等同于切比雪夫距离。
三、 特征预处理
在 KNN 中,距离计算受特征量级影响巨大。例如“身高(米)”和“收入(万元)”,收入的数值波动会完全掩盖身高的影响。
归一化 (MinMaxScaler):将数据映射到[0, 1] 之间。缺点是易受极值(Outliers)影响。
from sklearn.preprocessing import MinMaxScaler
# 创建归一化对象,默认区间为[0, 1]
transfer = MinMaxScaler(feature_range=(0, 1))
# 对原数据集进行归一化处理
x_train_scaled = transfer.fit_transform(x_train)
# 输出归一化后的数据
print(x_train_scaled)标准化 (StandardScaler):将数据转换为均值为 0,标准差为 1 的正态分布。这是比较推荐的做法。
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train_scaled = transfer.fit_transform(x_train)
# 输出标准化后的数据
print(x_train_scaled)
print("均值:", transfer.mean_)
print("方差:", transfer.var_)
print("标准差:", transfer.scale_)
四、 鸢尾花分类案例
该案例是机器学习的经典入门项目。通过对花萼和花瓣的长宽进行建模,我们可以准确预测鸢尾花的种类。
1. 加载数据集
鸢尾花数据集包含150个鸢尾花样本,每个样本有四个特征,分别是花萼(sepal)长度、花萼宽度、花瓣(petal)长度和花瓣宽度,以及它们所属的鸢尾花品种。
150个鸢尾花样本包括三种不同的品种:山鸢尾(Setosa)、变色鸢尾(Versicolor)、维吉尼亚鸢尾(Virginica),每种品种各有50个样本。
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
print("特征数据:", iris.data)
print("标签数据:", iris.target)
print("特征对应的名称:", iris.feature_names)
print("标签对应的名称:", iris.target_names)
print("数据集描述:", iris.DESCR)2. 切分数据集
为了验证模型的泛化能力,我们按照 80% 训练集和 20% 测试集的比例进行切分。
random_state参数用于设置随机种子,以确保每次运行代码时切分结果相同,便于结果的复现。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=23)
print("训练集特征数据:\n", x_train, "个数:", len(x_train))
print("训练集标签数据:\n", y_train, "个数:", len(y_train))
print("测试集特征数据:\n", x_test, "个数:", len(x_test))
print("测试集标签数据:\n", y_test, "个数:", len(y_test))3. 特征工程
from sklearn.preprocessing import StandardScaler
# 标准化
transfer = StandardScaler()
# 训练并转换训练集数据
x_train = transfer.fit_transform(x_train)
# 转换测试集数据,无需重新训练
x_test = transfer.transform(x_test)4. 模型训练
from sklearn.neighbors import KNeighborsClassifier
# 模型训练 - KNN分类
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)5. 模型预测与评估
from sklearn.metrics import accuracy_score
# 模型预测
y_predict = estimator.predict(x_test)
# 模型评估
# 方法一:直接计算准确率
print("准确率:", estimator.score(x_test, y_test))
# 方法二:预测结果并对比
print("准确率:", accuracy_score(y_test, y_predict))五、超参数选择
K 值的选取对模型效果至关重要:
K 值过小:容易受到异常点(噪声)影响,模型过于复杂,容易导致过拟合。
K 值过大:容易受到样本均衡问题影响,模型过于简单,容易导致欠拟合。
交叉验证
交叉验证(Cross-Validation)是一种用于评估机器学习模型性能、防止过拟合的统计学方法。
将数据集拆分为N个大小相等的子集(折,folds),其中一份作为验证集,其他作为训练集。
多次对模型进行评估,取平均值作为模型的最终得分。
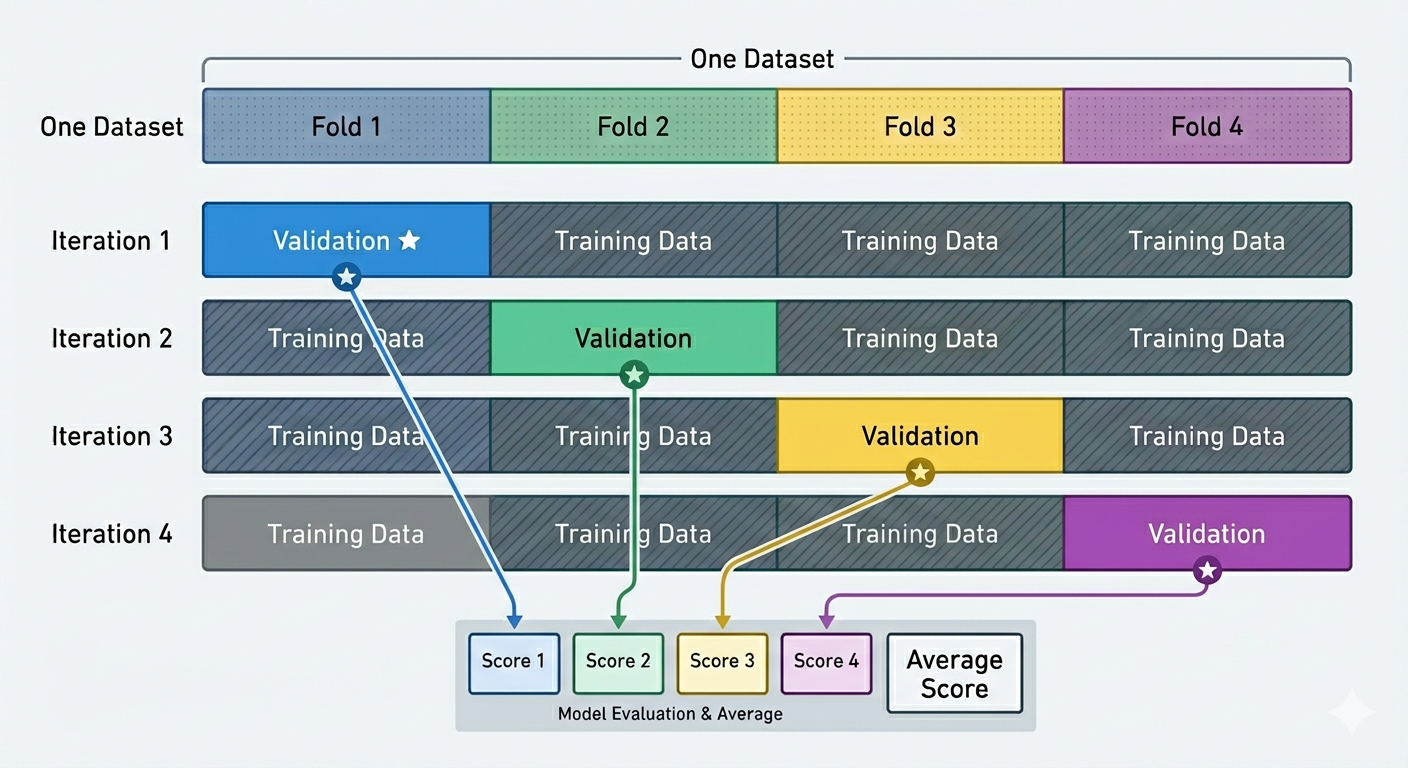
网格搜索
网格搜索(Grid Search)是一种自动化的超参数优化技术,通过穷举指定的参数值组合,寻找模型在验证集上的最优超参数。
它通过遍历预设参数列表的笛卡尔积来训练模型并评估表现,常用于少数量的超参数调优。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 定义搜索范围
param_dict = {"n_neighbors": range(1, 11)}
estimator = GridSearchCV(KNeighborsClassifier(), param_grid=param_dict, cv=4)
estimator.fit(x_train, y_train)
# 结果
print("最佳评分:", estimator.best_score_)
print("最佳超参数:", estimator.best_params_)
print("最佳估计器:", estimator.best_estimator_)
print("交叉验证结果:", estimator.cv_results_)六、手写数字识别案例
MNIST数据集是机器学习和计算机视觉领域的经典手写数字识别基准数据集。它包含60,000张训练图像和10,000张测试图像,所有图像均为28x28像素的灰度图,涵盖0-9的手写数字。
模型训练
MNIST CSV 文件中第一列为“标签”,其余784列为图像的像素值。
使用 joblib 保存训练好的模型,后续使用时无需再次训练模型。
import joblib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
def train_model():
# 加载数据
df = pd.read_csv("./MNIST/mnist_train.csv")
x = df.iloc[:, 1:]
y = df.iloc[:, 0]
# 数据归一化
x /= 255
# 切分数据集为训练集和测试集,按照80%训练集和20%测试集的比例
# stratify参数用于按照标签的分布进行分层抽样,确保数据均衡
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=23, stratify=y)
# 模型训练 - KNN分类
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 模型评估
print("准确率:", estimator.score(x_test, y_test))
# 保存模型
joblib.dump(estimator, "./models/knn_model.pkl")
print("模型已保存到 ./models/knn_model.pkl")模型使用
加载一张 28x28 像素的灰度图片,需要将像素矩阵展平为一维矩阵,才能进行后续的预测。
def use_model(path: str):
# 加载图片
x = plt.imread(path)
print("图片已加载,形状:", x.shape)
# 加载模型
estimator = joblib.load("./models/knn_model.pkl")
print("模型已加载")
# 将二维图像展平为一维向量
x = x.reshape(1, -1)
print("图片数据已展平,形状:", x.shape)
# 模型预测
prediction = estimator.predict(x)
print("预测结果:", prediction)