布隆过滤器
场景引入
让我们思考一个场景:现在有 10 亿条数据,且没有排序,要怎么快速找出其中重复的数据?
遇到这个问题,首先想到的肯定是使用 HashMap,将数据作为 Key,该数据出现的次数作为 Value,最终统计出所有数据出现的次数。
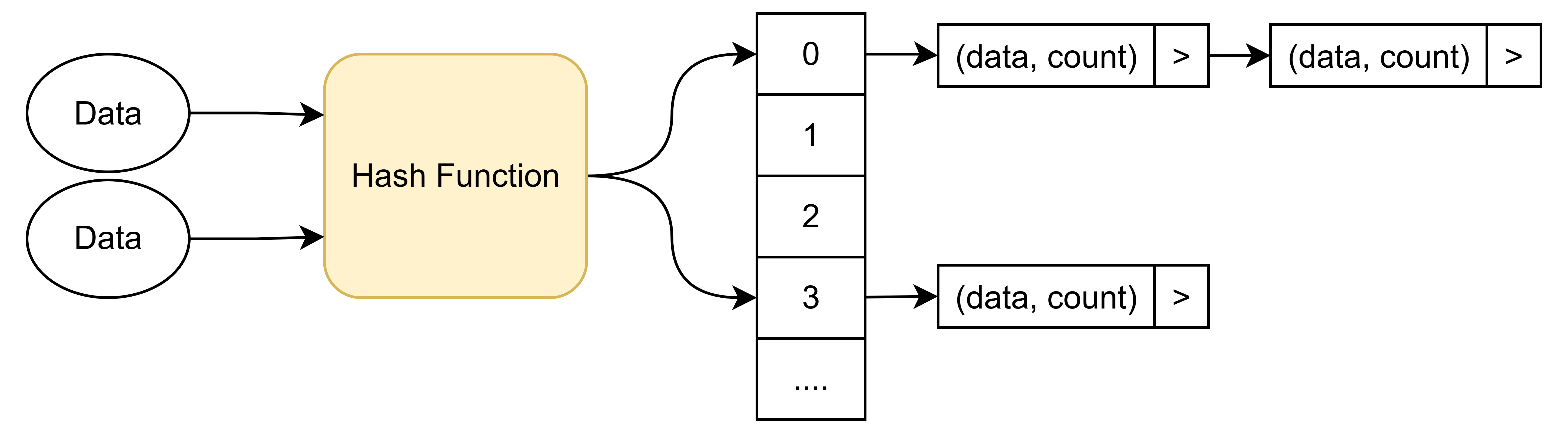
但是,HashMap 是否存在问题呢?假设,10 亿数据都没有重复,即每条数据都要单独创建一个节点,Key 和 Value 都是 int 类型,每个 int 占用 4 字节,即每一条数据 Key + Value 总共占用 8 字节,10 亿条数据需要大约 7.5GB 内存,这还不包括数据结构占用的其他内存。
什么是布隆过滤器
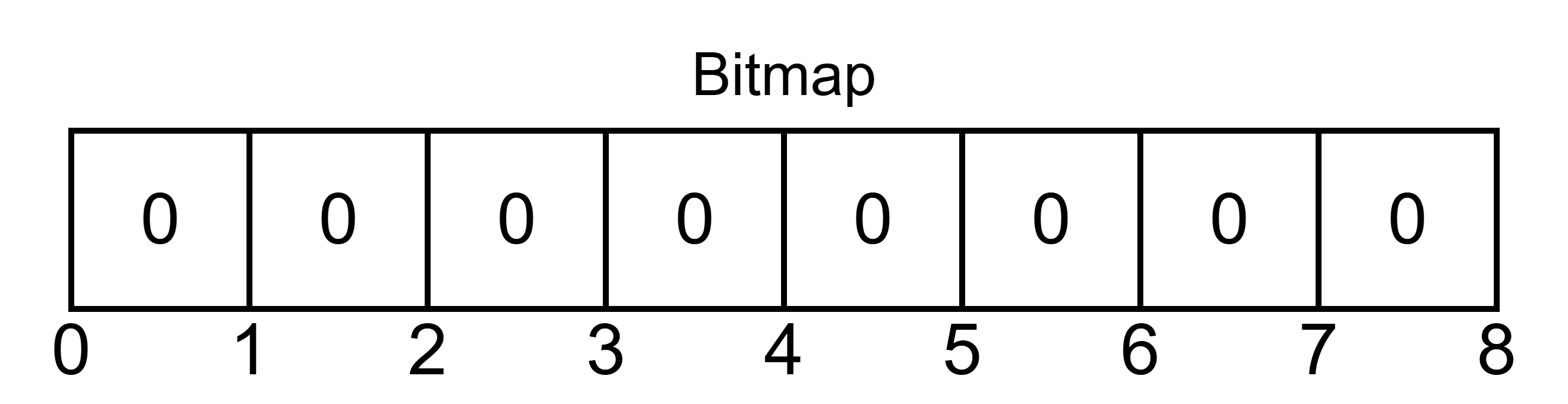
布隆过滤器的数据结构是一组 bit 向量,每个字节由 8 个比特组成,每一位都有 0/1 两种状态,初始状态下所有值均为 0。
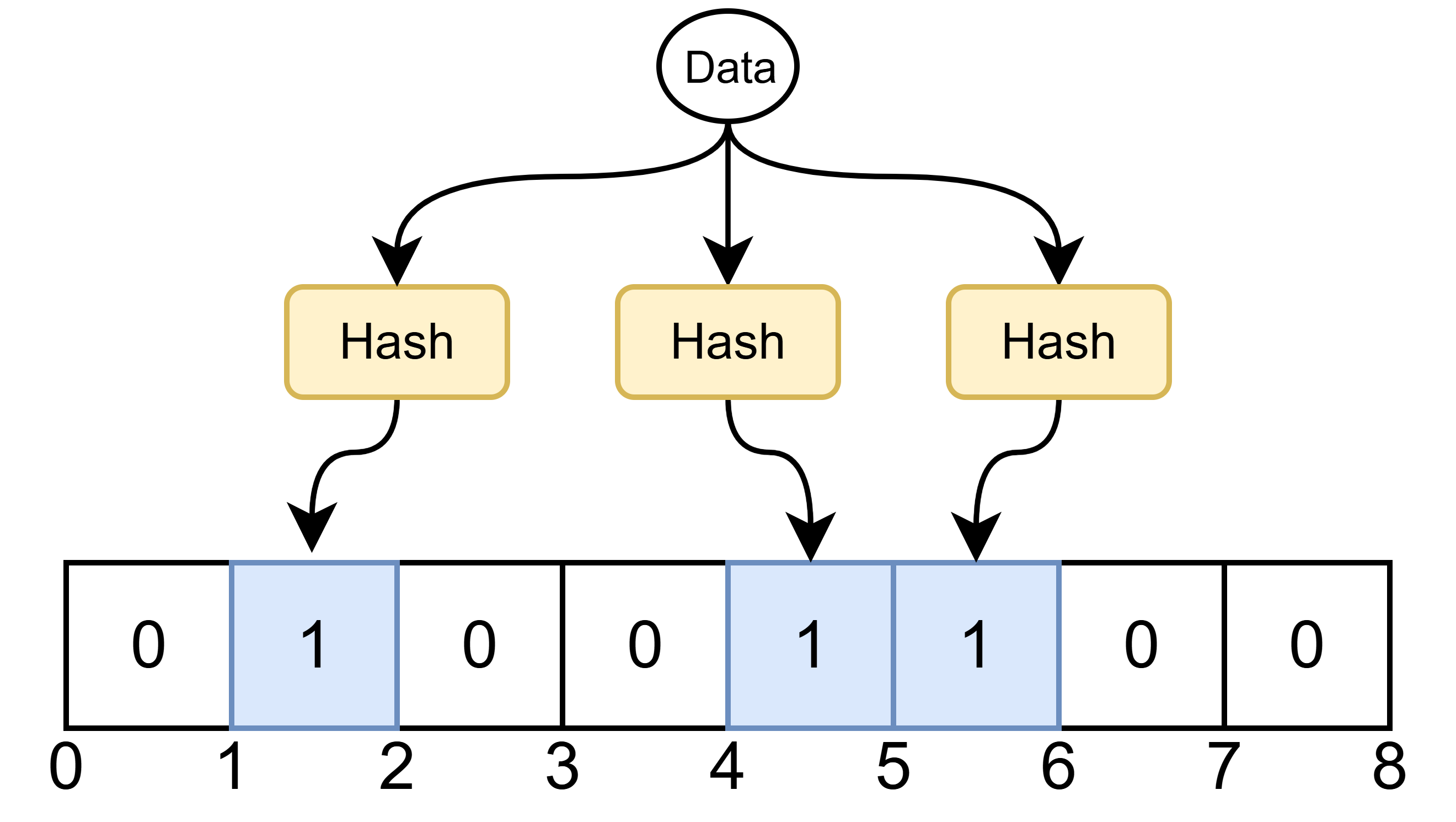
回忆 HashMap 将一个数据通过 Hash 函数计算得到数组的一个索引,布隆过滤器也是一样的做法,将索引对应的比特值置 1 表示数据已存在。若只有一个 Hash 函数可能会因为两个不同的数据产生 Hash 碰撞,误以为原本不存在的数据已存在。为了降低误差,通常布隆过滤器会使用多个 Hash 函数将多个 bit 置 1。
误判率
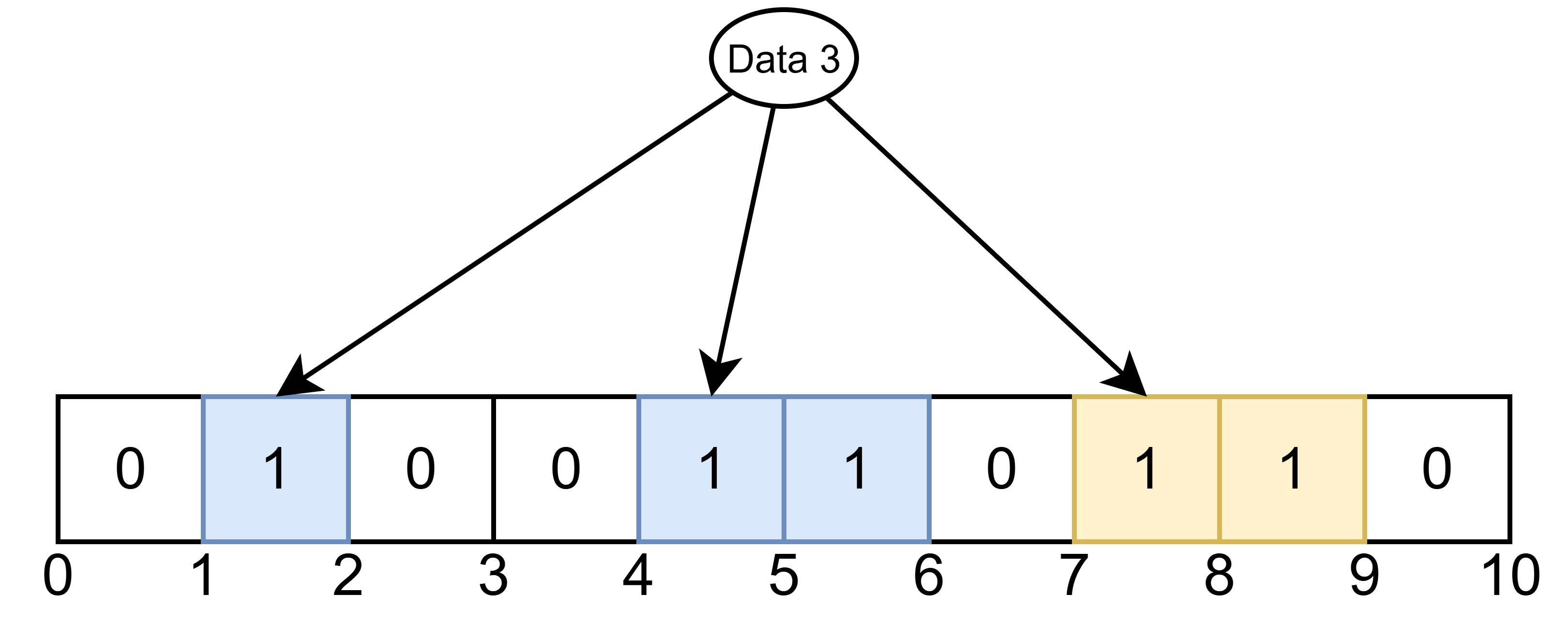
假设,在布隆过滤器中添加 2 个元素 Data 1 与 Data 2,并将其中 5 个位置 1。
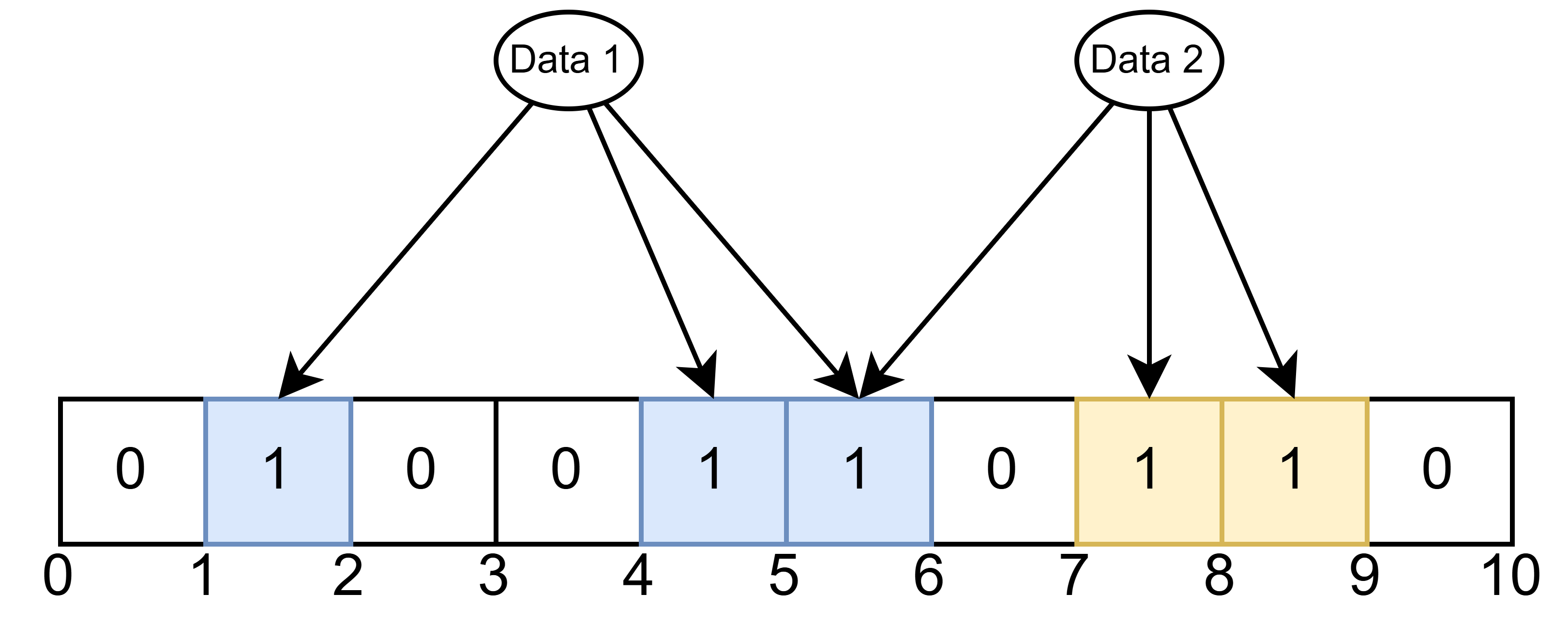
此时,查询一个从未加入过布隆过滤器的数据 Data 3,发现通过多个 Hash 函数对应的索引值都是 1,得出结论: Data 3 存在。这种误判的情况肯定是我们所不希望看到的!
简单计算一下误判率,假设布隆过滤器的大小为 m 个比特位,添加一条数据其中一位是 1 的概率就是相反数 1/m,反之,其中一位不为 1 的概率则是:
又因为每个数据必须与多个 Hash 函数计算得出多个索引位置 1,假设布隆过滤器使用了 k 个 Hash 函数:
根据重要极限,当布隆过滤器的长度趋近于无穷时,其中一位不为 1 的概率为:
另外,我们会不断的向布隆过滤器中添加数据,假设已经添加了 n 个元素:
当添加 n 条数据后,出现误判的概率(即,k 个对应位都为 1 的概率):
结论:当 Hash 函数数量确定时, bit 向量长度 m 增加误判率会减低,而随着数据量 n 增加,误判率也会随着提升。
Hash 函数数量
从前面的计算能看出,布隆过滤器的误判率与 Hash 函数的数量息息相关,到底要使用多少个 Hash 函数比较合适呢?
接着上面的计算,对等式两边同时取对数:
再对两边同时求导得:
令 f{}'(k) = 0:
使用自然对数的性质变化一下形式:
设 x = e^{\frac{-kn}{m}}得:
由此可见取值范围 x \in (0, 1) 且 x = 1 - x,即:
此时,f(k) 取得极小值,布隆过滤器的误判率最小。
删除元素
布隆过滤器本身是不支持删除的,因为其只将数据通过多个 Hash 函数计算出的索引位置 1,并不保存实际数据。若想要删除某个元素,就必须再次通过多个 Hash 函数将所有的 1 都置为 0。
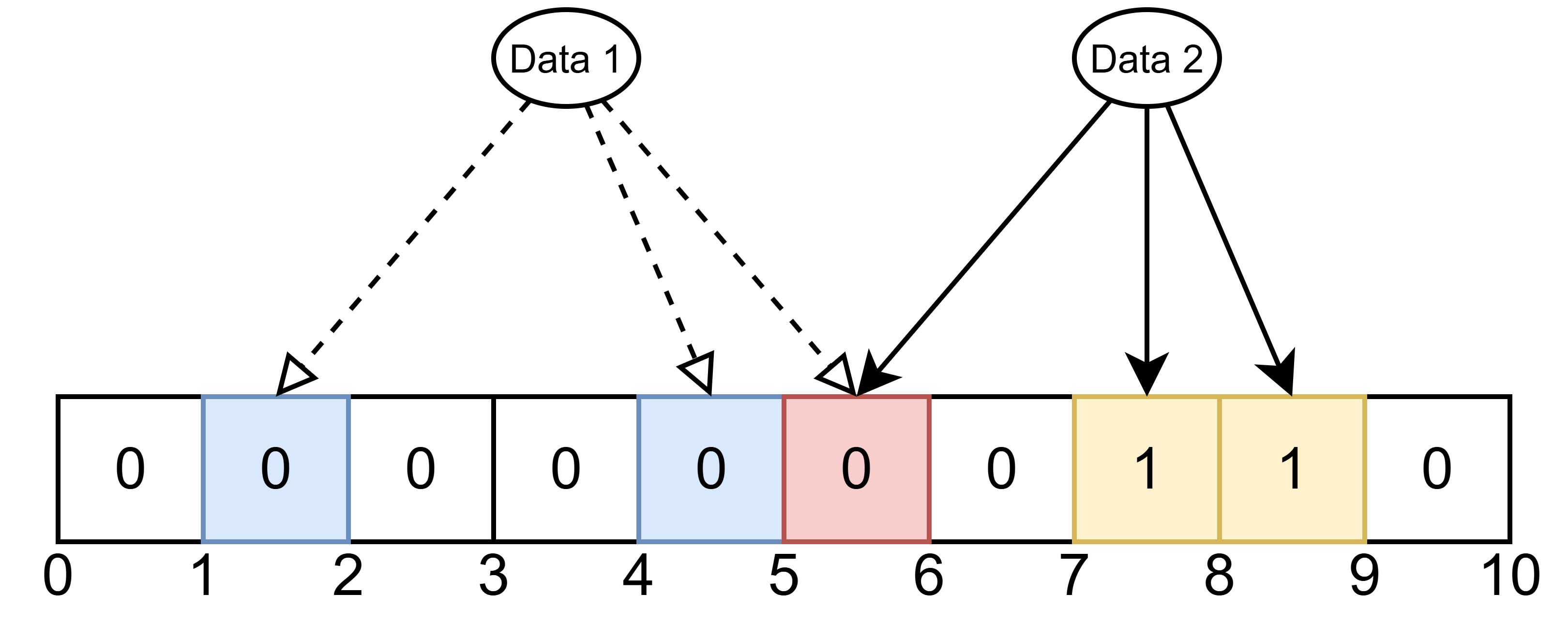
如图所示,当将 Data 1 所对应的几个比特位都置为 0 时影响到了 Data 2,下次若查询 Data 2 时,发现其中有一个比特位不为 1,则返回 Data 2 不存在。实际上我们删除的是 Data 1,不应该影响到 Data 2!
布隆过滤器若想要删除元素,就只能重新创建、重新添加元素。或者,使用能够删除元素的布谷鸟过滤器。
手写布隆过滤器
结合 Redis 使用 bitmap 实现布隆过滤器,这里使用布隆过滤器做一个白名单,只有在白名单中的用户可以访问,否则禁止访问。
当项目启动时,自动向布隆过滤器中添加一些白名单用户,同时对外提供一个 contains 方法用于判断某个元素是否存在。
@Component
public class WhiteListBloomFilter {
private final String key = "whitelist";
private final List<Integer> whiteList = List.of(10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20);
@Resource
private RedisTemplate<String, Object> redisTemplate;
@PostConstruct
public void init() {
whiteList.forEach(id -> {
String user = UserConstant.USER_CACHE_KEY_PREFIX + id;
// 多个 hash 函数
int hashCode = Math.abs(user.hashCode());
// 假设布隆过滤器的长度为 2^32
long index = (long) (hashCode % Math.pow(2, 32));
// 在 Redis 中将对应位置 1
redisTemplate.opsForValue().setBit(key, index, true);
});
}
public boolean contains(String id) {
String user = UserConstant.USER_CACHE_KEY_PREFIX + id;
// 多个 hash 函数
int hashCode = Math.abs(user.hashCode());
long index = (long) (hashCode % Math.pow(2, 32));
return Boolean.TRUE.equals(redisTemplate.opsForValue().getBit(key, index));
}
}在 Service 层查询时,优先通过布隆过滤器过滤非法用户,而后再查询 Redis 与 MySQL。
需要注意的时,由于布隆过滤器存在误差,所以通过布隆过滤器筛选的数据只能代表可能存在,但没通过筛选的数据一定不存在!若无法接收误差,通过筛选的数据还需再次校验!!
@Override
public User getUserById(String id) {
// 先查布隆过滤器
boolean contains = whiteListBloomFilter.contains(id);
if (!contains) {
// 肯定不在白名单中
return null;
}
// 再查缓存
String key = USER_CACHE_KEY_PREFIX + id;
User user = (User) redisTemplate.opsForValue().get(key);
if (user != null) {
return user;
}
// 双检加锁策略
synchronized (this) {
user = (User) redisTemplate.opsForValue().get(key);
if (user == null) {
// 缓存不存在,则查数据库
user = this.lambdaQuery().eq(User::getId, id).one();
// 回写缓存
redisTemplate.opsForValue().set(key, user);
}
}
return user;
}